构建企业级推荐系统 第2章 推荐算法基础
构建企业级推荐系统 第2章 推荐算法基础
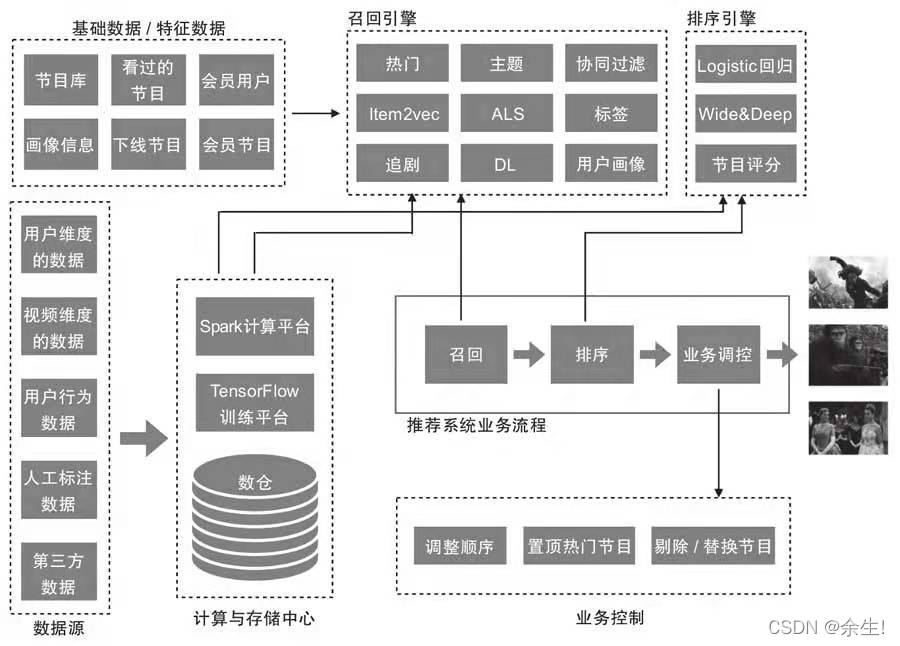
余生推荐系统范式
- 完全个性化范式
- 群组个性化范式
- 完全非个性化范式
- 标的物关联标的物范式
- 笛卡尔积范式


2. 推荐算法3阶段pipeline架构

3. 推荐召回算法
3.1 完全非个性化范式
对所有的用户推荐一样的标的物列表,比如最热榜、最新榜
可以基于简单的计数统计来生成推荐,基本不会用到复杂的机器学习。可能用整合各类用户行为数据。
优点 :可解释性强,根据从众心理,效果也可以。可以作为冷启动或者默认的推荐算法。
3.2 完全个性化范式
3.2.1 基于内容的个性化推荐算法
核心:只依赖用户自己的历史行为而不必知道其他用户的行为,通过用户对标的物的操作,为用户附加标的物的属性,作为用户的兴趣标签。
可以分为以下两类:
- 基于用户特征表示的推荐
将标的物属性通过TF-IDF或者LDA算法转化为特征向量,对用户操作过的标的物的特征向量加权平均作为用户的特征向量,利用用户特征向量和标记物特征向量计算余弦值得到相似度。 - 基于倒排索引的推荐
倒排索引概念
搜索领域 引自:https://www.cnblogs.com/zlslch/p/6440114.html
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
基于用户的历史行为,构建用户兴趣画像(标的物标签),构建标签与标的物的倒排索引查询表。
用户的每个兴趣标签和标签到标的物的关联是有权重的。

优点:直观、可解释性强
缺点:推荐新颖性不足
3.2.2 基于协同过滤的推荐算法
"物以类聚,人以群分“的朴素协同过滤,协同过滤的核心思想是计算标的物之间的相似性以及人之间的相似性。
- . 构建用户对标的物的操作行为矩阵
- 行向量之间的相似度是用户的相似度
- 列向量之间的相似度是物品之间的相似度
相似度计算可以采用余弦相似度
在互联网产品中一般采用基于物品的协同过滤,因为用户增长较快,标的物的变化则比较小,当然这也是有例外的(新闻,短视频)
优点:直观、计算简单、易于分布式、不依赖于其他信息
3.2.3 基于模型的推荐算法
基于模型的推荐算法有三类预测方式:
- 预测标的物的评分,利用评分的高低表示对标的物的喜好
eg:矩阵分解算法 - 预测对标的物的喜好概率,通过概率大小反应用户对标的物的喜好程序
eg: logistic回归算法 - 将每个标的物看做一类,预测用户消费的下一个或几个标的物类别
eg: Youtube [Deep Nerual Network for YouTube Recommendations]
3.3 群组个性化范式
现将用户进行分组
3.3.1 基于用户画像圈人的推荐
基于用户的人口统计学数据或者用户行为数据构建用户画像,对同一批人做针对性运营
3.3.2 基于聚类算法的推荐
- 将用户嵌入一个高维空间向量,基于用户的向量表示做聚类
采用基于内容推荐的思路:,构建用户的特征向量,有了特征向量之后进行聚类,对类内的所有用户的特征向量加权平均作为该类的特征向量。然后通过用户和标的物的内积作为相似度
基于用户的协同过滤思路:
利用矩阵分解得到用户的特征向量
通过词嵌入构建标的物向量,用户向量式是操作过的标的物向量的均值
基于计数统计 - 构建用户关系图,基于图做聚类
3.4 标的物关联标的物范式
为每个标的物推荐一组标的物,其核心是从一个标的物关联到另一组标的物
3.4.1 基于内容的推荐
利用向量来描述标的物,计算向量之间的相似度来计算标的物之间的相似度。
文本内容表示表示可以利用TF-IDF
文档可以用LDA模型将文档表示为主题及相关词的概率,计算两个文档某个主题词的相似度,所有主题加权平均得到两个文档的相似度。
3.4.2 基于用户行为的推荐
- 常用的矩阵分解算法,将用户行为矩阵分解为用户特征矩阵和物品特征矩阵
- 采用嵌入的思路,将用户的行为看成文档,标的物看做词,利用word2vec的思想
- 将用户对标的物的所有操作行为映射到一个二维表上
- 采用购物篮的思路
3.4.3 基于标签的推荐
通过标的物的标签构建向量,长度是总的标签数量,这是一个稀疏向量,然后计算相似度
3.4.4 基于标的物聚类的推荐
按照某一个维度进行聚类;如果某一类较少,通过一些如热门推荐的策略来补充
3.5 笛卡尔积范式
先采用标的物关联标的物的范式来计算待推荐的标的物列表,再根据用户的兴趣进行重排,增补(用户兴趣),删除(推荐过的)
4. 排序算法
排序模块用到的特征:
- 用户侧:性别、年龄、地域、购买力、家庭结构等
- 商品侧:商品描述信息、价格、标签等
- 上下文及场景特征:位置、页面、是不是周末等
- 交叉特征:用户侧和商品侧的交叉特征等
- 用户的行为特征:用户点击、收藏、购买、观看等
参考资料:Learning to rank for information retrieval
常用的排序学习算法框架有pointwise、pairwise、listwise
pointwise 学习单个样本 x,y
pairwise 学习一对有序对 <x1,x2>, y12, 推荐系统常用
listwise学习一个有序序列 <x1,x2,x3,x4>, s1
常用的算法
4.1 Logistic回归模型
是特征,是权重
4.2 GBDT模型
生成多个决策树,集成学习
GBDT模型可以抽象为一个特征处理器,特知道新的特征,这也是GBDT+LR(Facebook)的核心思路
Wide&Deep 模型
谷歌提出,将传统模型和深度学习模型结合
Wide部分是logistic回归子类的传统模型,起到记忆作用,从历史数据中发现item之间的相关性;Deep部分是起泛化作用,用户发现新的特征组合
5. 推荐算法落地需要关注的几个问题
5.1 一定要用排序吗
排序阶段不是必须的,可以快速上线
增加排序的两个原因:
- 标的物池太大
- 工程上模块化,人员分工精简
5.2 服务于用户的形式
- 将推荐结果直接保存在数据库;简单,需要存储资源,初期建议采用。
- 保存核心特征,在请求时通过简单技术得到推荐结果;要求较高,服务精细
5.3 推荐系统评估
推荐系统是服务于公司商业目的的,实现盈利目标,提升用户体验,使用时长,DAU等






