【Juicy-Bigdata】Hadoop之HDFS核心进程剖析

【Juicy-Bigdata】Hadoop之HDFS核心进程剖析
余生HDFS核心进程剖析
HDFS体系结构
主从结构,主节点:NameNode 从节点:DATaNode, 都支持多个
SecondaryNameNode 辅助节点
NameNode节点介绍
整个文件系统的管理节点
- 维护整个文件系统的文件目录树
- 文件/目录信息
- 每个文件对应的数据块列表(一个文件可能在多个块上)
- 负责接受用户 请求

fsimage
文件信息,目录树…
1 | hdfs oiv -p XML -i fsimage_ -o fsi.xml |

edits
事务文件,记录上传状态
secondarynameNode做这个事情:会定期合并到fsimage
seen_txid
edits文件尾数,保证数据一致性
VERSION
格式化之后产生的信息
- 维护了两份关系
- File和Block list的关系,元数据用150字节
- DataNode与Block的关系
SecondaryNameNode
-
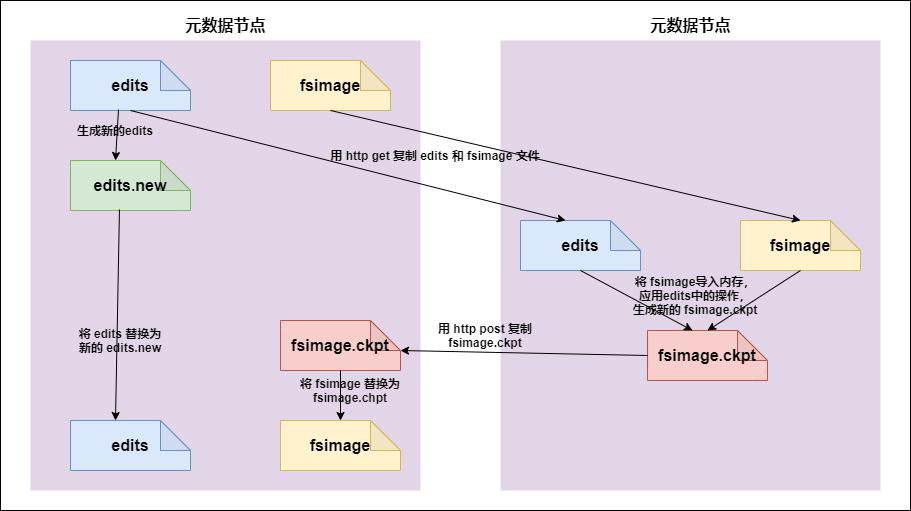
负责定期将edits中的内容合并到fsimages

- secondary namenode 询问namenode 是否需要checkpoint。直接带回namenode是否检查结果。默认一小时合并一次,操作次数达到
- secondary namenode 请求执行checkpoint。
- namenode 滚动正在写的edits 日志,namenode 停止使用edits,暂时将新写操作放入一个新的文件中(edits.new)
- 将滚动前的编辑日志和镜像文件拷贝到secondary namenode。
- secondary namenode 加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint 到namenode。
- namenode 将fsimage.chkpoint 重新命名成fsimage。
-
HA架构中没有SecondaryNameNode,合并操作由standby NameNode实现
HA:多个NameNode,由备用的NameNode负责
DataNode
-
按照固定的大小划分每一个块,默认128M,Hadoop1中是64M
-
如果一个文件小于数据块大小,不会占用整个
-
Replication 副本
文件的各个block 的具体存储管理由DataNode 节点承担。每一个block 都可以在多个DataNode 上。DataNode 需要定时向NameNode 汇报自己持有的block 信息。存储多个副本(副本数量也可以通过参数设置dfs.replication,默认是3)
抽象为block块的好处
- 一个文件可能大于集群中任意一个磁盘
- 使用块抽象而不是文件可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力和可用性
块缓存
通常datanode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显式地缓存在datanode的内存中,以堆外块缓存(off-heap block cache)的形式存在。默认情况下,一个块仅缓存在一个datanode的内存中,当然可以针每个文件配置datanode的数量。作业调度器(用于MapReduce、Spark和其他框架的)通过在缓存块的datanode上运行任务,可以利用块缓存的优势提高读操作的性能。例如,连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。
NameNode故障恢复
secondaryNameNode中是包含fsimage和edits的,因此可以把这些赋值给NameNode
- 杀死NameNode进程
- 删除NameNode的fsimage和edits
- 将secondaryNameNode的fsimage和edits拷贝到NameNode
- 重新启动NameNode
HDFS常用命令行
1 | hdfs hfs -help |
HDFS回收站
- 回收站目录:/user/用户名/.Trash
- core-site.xml : fs.trash.interval
HDFS安全模式
启动自检,也可以手动退出,检查数据块的完整性
假设副本数时3,如果只存在2个副本,那么比例是0.66,hdfs默认的副本率是0.99,。此时系统会自动复制副本到其他datanode。如果系统中有5 个副本,超过我们设定的3 个副本,那么系统也会删除多于的2 个副本。
在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。
定时上传数据至HDFS

1 | !/bin/bash |
HDFS的高可用和高扩展
- NameNode节点宕机?
- NameNode节点内存不够?
HDFS的高可用(HA)
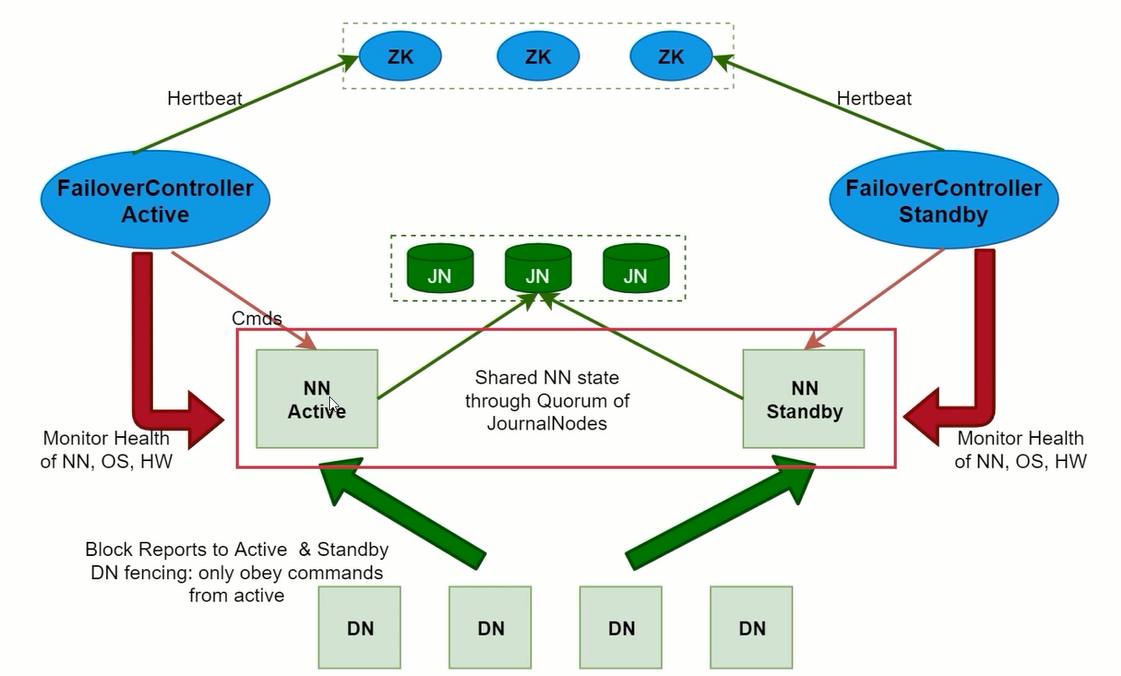
- HA表示一个集群中存在多个NameNode,只有一个是Activate状态,其他的是Standby状态
- ActiveNameNode(ANN)负责所有来自客户端的操作,StandbyNameNode(SNN)负责用来同步ANN的状态信息
- 使用HA的时候,不能启动SecondaryNameNode
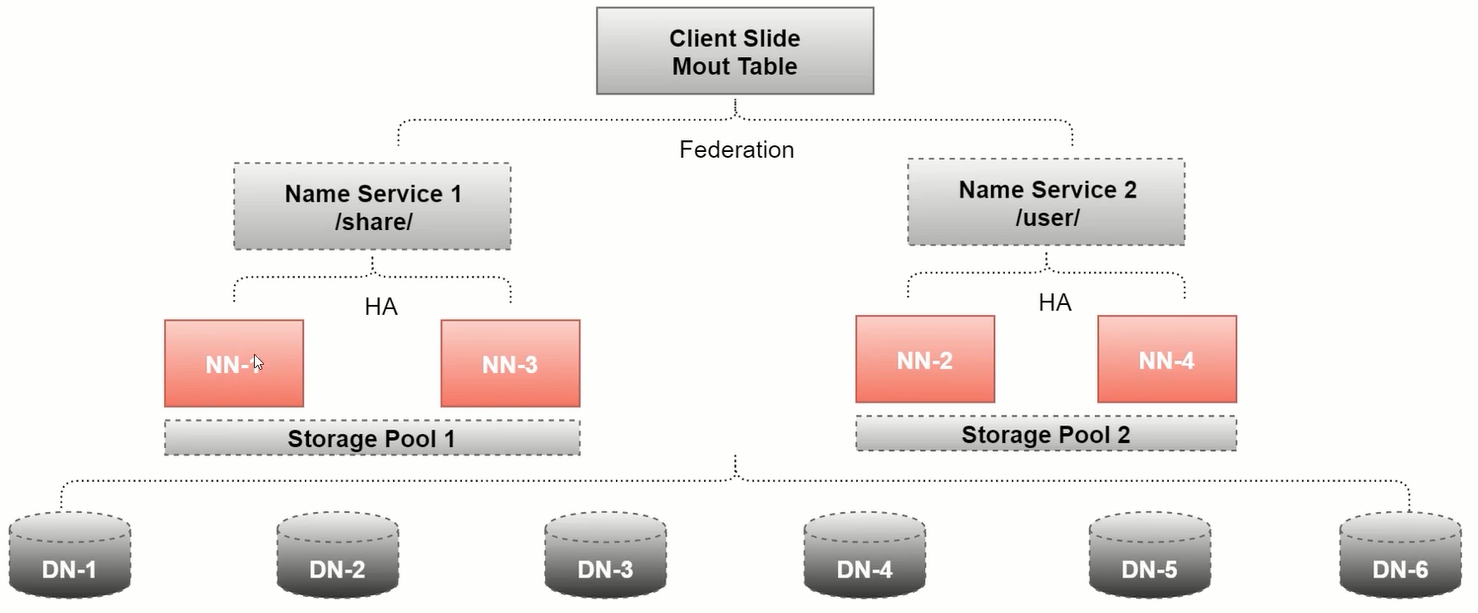
HDFS的高扩展(Federation)
负责单一命名空间