【Juicy-Bigdata】Hadoop之MapReduce

【Juicy-Bigdata】Hadoop之MapReduce
余生MapReduce
MapReduce思想
先分再合,分而治之
Map: 负责拆分,彼此之间没有依赖
Reduce:负责合并
MapReduce 设计思想
抽象编程模型:

map:对一组数据元素进行某种重复式的处理
reduce:对Map的中间结果进行处理

统一架构,隐藏底层细节
MapReduce特点
高容错性
适合海量数据的离线处理
可扩展
局限性
- 实时计算性能差
- 不能进行流式计算
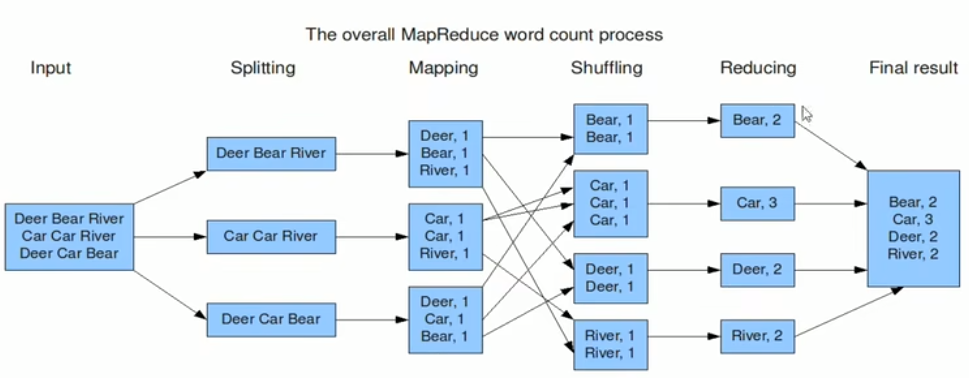
实战WordCount
深入MapReduce
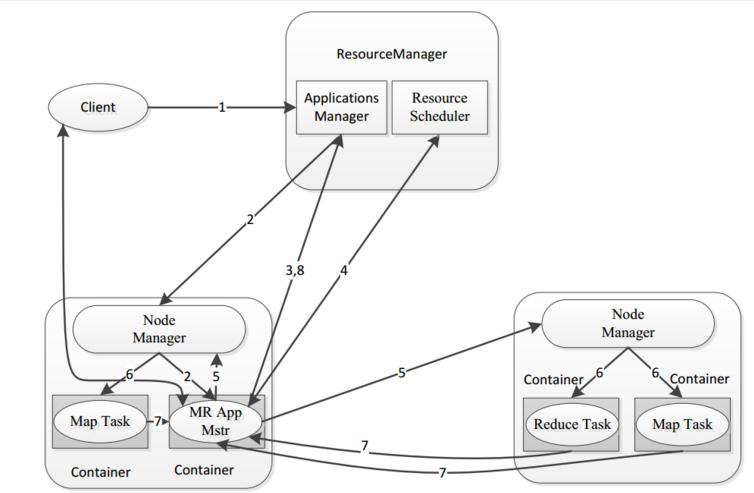
停止提交的任务
1 | yarn application -kill app_id |
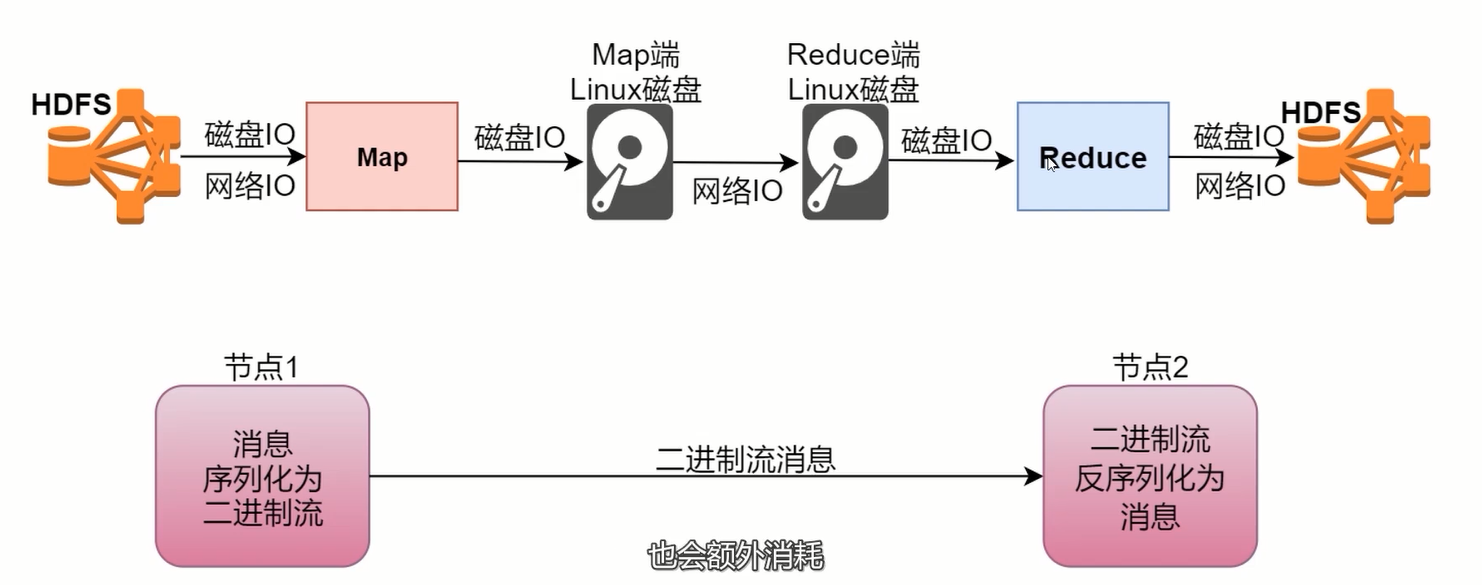
Shuffle过程剖析
Hadoop中的序列化机制
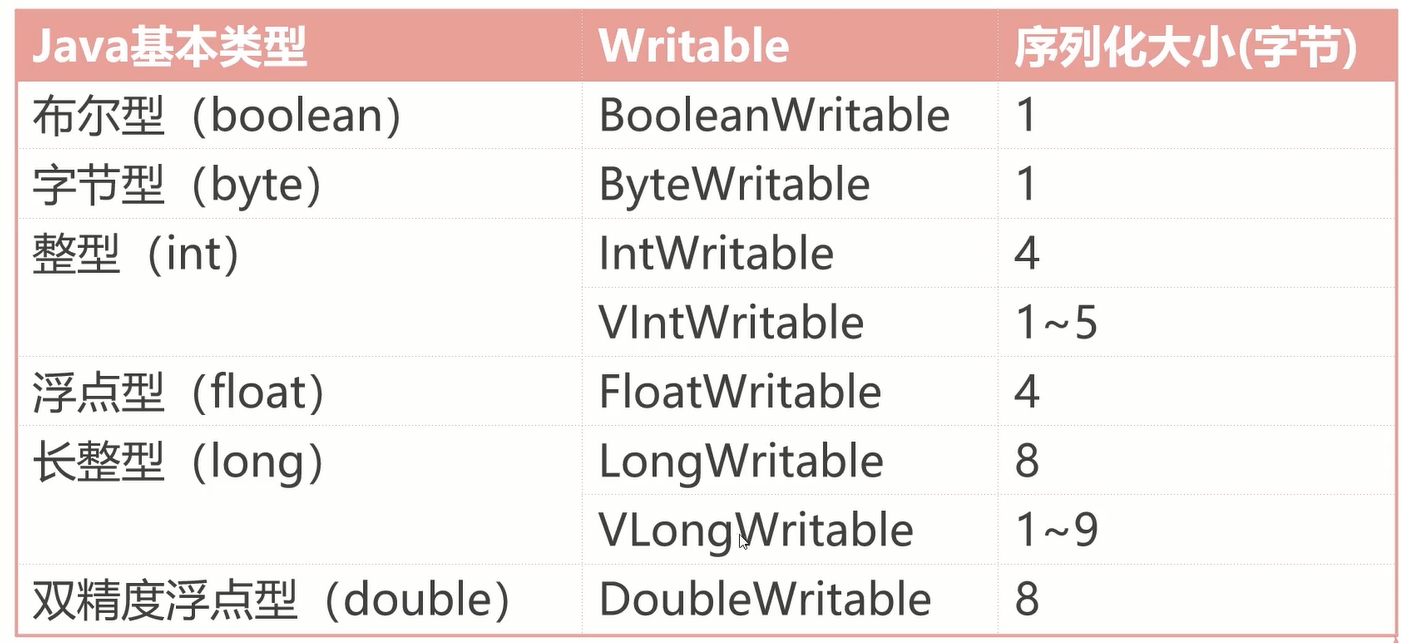
常用的Writeable实现类
- 紧凑:高效使用空间
- 快速:快速数据读写
- 可扩展:透明读取
- 互操作:支持多语言交互
源码解读 TODO
MapReduce 性能优化
小文件问题
使用容器
- SequenceFile
- MapFile
数据倾斜
数据频率倾斜:某一个区域的数据量远大于其他区域
解决方案:
- 数据打散






