【Juicy-Bigdata】Hive SQL底层执行原理

【Juicy-Bigdata】Hive SQL底层执行原理
余生Hive底层执行架构
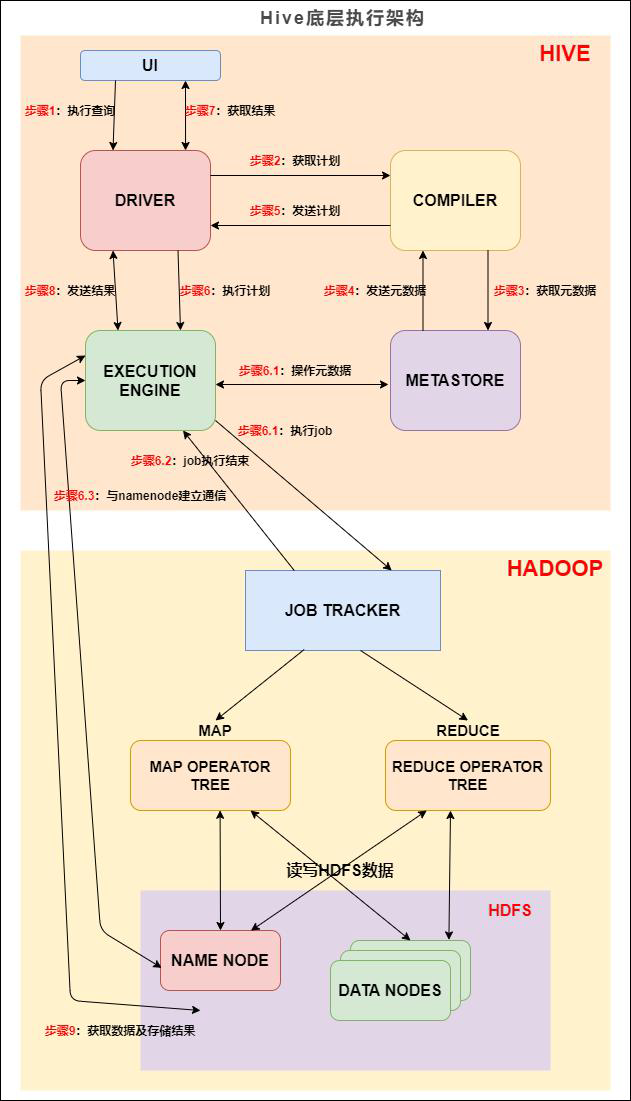
基本流程
-
UI调用DIRVE接口
-
DRIVE创建会话句柄,发送到编译器
-
- 编译器从元数据存储中获取本次查询所需要的元数据,该元数据用
于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
- 编译器从元数据存储中获取本次查询所需要的元数据,该元数据用
-
:编译器生成的计划是分阶段的DAG,每个阶段要么是map/reduce 作业,
要么是一个元数据或者HDFS 上的操作。将生成的计划发给DRIVER。
如果是map/reduce 作业,该计划包括map operator trees 和一个reduce
operator tree,执行引擎将会把这些作业发送给MapReduce : -
步骤6、6.1、6.2 和6.3:执行引擎将这些阶段提交给适当的组件。在每个
task(mapper/reducer) 中,从HDFS 文件中读取与表或中间输出相关联的数据,
并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时
HDFS 文件中(如果不需要reduce 阶段,则在map 中操作)。临时文件用于向
计划中后面的map/reduce 阶段提供数据。 -
步骤7、8 和9:最终的临时文件将移动到表的位置,确保不读取脏数据(文件重
命名在HDFS 中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接
从HDFS 读取,然后通过Driver 发送到UI。
HIVE SQL编译过程
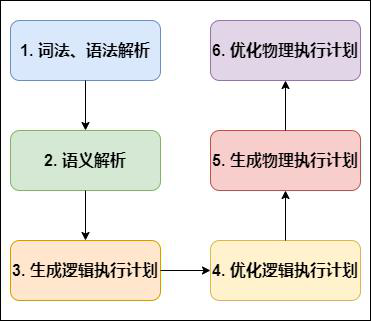
HIVE SQL编译为MapReduce原理
TODO








