【Juicy-Bigdata】Hive千亿级数据倾斜

【Juicy-Bigdata】Hive千亿级数据倾斜
余生Hive千亿级数据倾斜
从本质上说,发生数据倾斜的原因有两种:一是任务重需要处理大量相同的key的数据;二是任务读取不可分割的大文件
解决方案
空值引发的数据倾斜
表中有大量的 null 值,如果表之间进行 join 操作,就会有 shuffle 产生,这样所有的 null 值都会被分配到一个 reduce 中,必然产生数据倾斜
解决方案:
- 不让null值参与join操作
1 | select * |
- 给null随机赋值,这样他们的hash结果不一样,便会分配到不同的reduce中
1 | select * |
不同数据类型引发的数据倾斜
对于两个表 join,表 a 中需要 join 的字段 key 为 int,表 b 中 key 字段既有 string 类型也有 int 类型。当按照 key 进行两个表的 join 操作时,默认的 Hash 操作会 按 int 型的 id 来进行分配,这样所有的 string 类型都被分配成同一个 id,结 果就是所有的 string 类型的字段进入到一个 reduce 中,引发数据倾斜
解决方案
把int转为sring
1 | select * |
不可拆分大文件引发的数据倾斜
当对文件使用 GZIP 压缩等不支持文件分割操作的压缩方式,在日 后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取
- 解决方案
我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜, 在数据压缩的时候可以采用 bzip2 和 Zip 等支持文件分割的压缩算法
数据膨胀引发的数据倾斜

表连接时引发的数据倾斜
两表进行普通的 repartition join 时,如果表连接的键存在倾斜,那么在 Shuffle 阶段必然会引起数据倾斜
- 解决方案
使用mapjoin
MapJoin 是 Hive 的一种优化操作,其适用于小表 JOIN 大表的场景,由于表的 JOIN 操作是在 Map 端且在内存进行的,所以其并不需要启动 Reduce 任务也就不需要经过 shuffle 阶段,从而能在一定程度上节省资源提高 JOIN 效率
确实无法减少数据量引发的数据倾斜
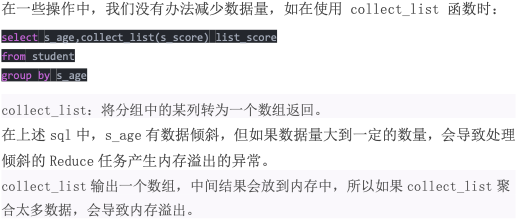
-
解决方法
调整 reduce 的内存大小使用 mapreduce.reduce.memory.mb 这个配置。
围绕shuffle和数据倾斜的调优点
- Mapper 端的 Buffer 设置为多大? Buffer 设置得大,可提升性能,减 少磁盘 I/O ,但 是对内存有要求,对 GC 有压力; Buffer 设置得小, 可能不占用那么多内存, 但是可 能频繁的磁盘 I/O 、频繁的网络 I/O








